EU Datathon 2021

Reprex, a Dutch start-up enterprise formed to utilize open source software and open data, is looking for partners in an agile, open collaboration to win at least one of the three EU Datathon Prizes. We are looking for policy partners, academic partners and a consultancy partner. Our project is based on agile, open collaboration with three types of contributors.
With our competing prototypes we want to show that we have a research automation technology that can find open data, process it and validate it into high-quality business, policy or scientific indicators, and release it with daily refreshments in a modern API.
We are looking for institutions to challenge us with their data problems, and sponsors to increase our capacity. Over then next 5 months, we need to find a sustainable business model for a high-quality and open alternative to other public data programs.
The EU Datathon 2021 Challenge
To take part, you should propose the development of an application that links and uses open datasets. - our data curator team
Your application … is also expected to find suitable new approaches and solutions to help Europe achieve important goals set by the European Commission through the use of open data.” - this application is developed by our technology contributors
Your application should showcase opportunities for concrete business models or social enterprises. - our service development team is working to make this happen!
We use open source software and open data. The applications are hosted on the cloud resources of Reprex, an early-stage technology startup currently building a viable, open-source, open-data business model to create reproducible research products.
We are working together with experts in the domain as curators (check out our guidelines if you want to join: Data Curators: Get Inspired!).
Our development team works on an open collaboration basis. Our indicator R packages, and our services are developed together with rOpenGov.
Mission statement
We want to win an EU Datathon prize by processing the vast, already-available governmental and scientific open data made usable for policy-makers, scientific researchers, and business researcher end-users.
“To take part, you should propose the development of an application that links and uses open datasets. Your application should showcase opportunities for concrete business models or social enterprises. It is also expected to find suitable new approaches and solutions to help Europe achieve important goals set by the European Commission through the use of open data.”
We aim to win at least one first prize in the EU Datathon 2021. We are contesting all three challenges, which are related to the EU’s official strategic policies for the coming decade.
Challenge 1: A European Grean Deel
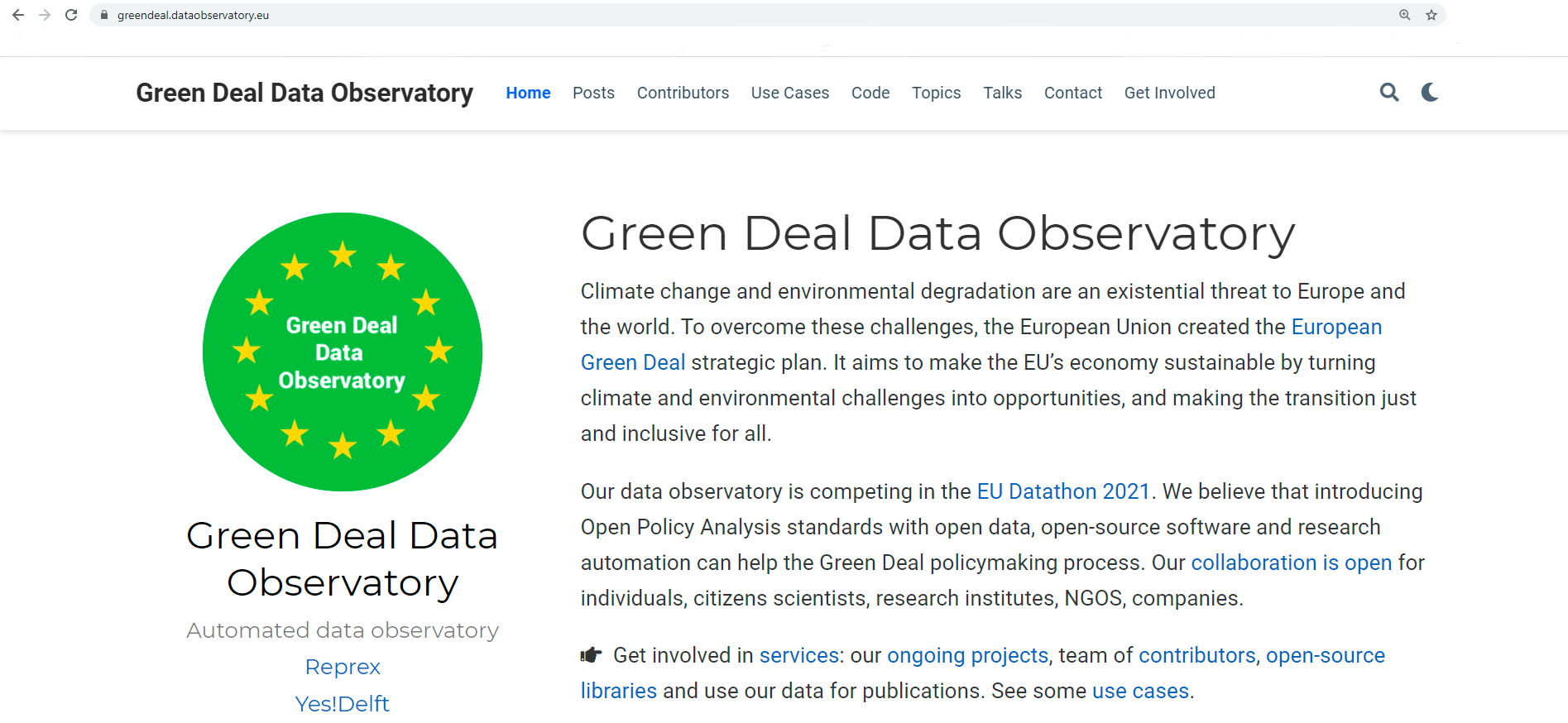
Challenge 1: A European Green Deal, with a particular focus on the The European Climate Pact, the Organic Action Plan, and the New European Bauhaus, i.e., mitigation strategies.
Climate change and environmental degradation are an existential threat to Europe and the world. To overcome these challenges, the European Union created the European Green Deal strategic plan, which aims to make the EU’s economy sustainable by turning climate and environmental challenges into opportunities and making the transition just and inclusive for all.
Our Green Deal Data Observatory is a modern reimagination of existing ‘data observatories’; currently, there are over 70 permanent international data collection and dissemination points. One of our objectives is to understand why the dozens of the EU’s observatories do not use open data and reproducible research. We want to show that open governmental data, open science, and reproducible research can lead to a higher quality and faster data ecosystem that fosters growth for policy, business, and academic data users.
We provide high quality, tidy data through a modern API which enables data flows between public and proprietary databases. We believe that introducing Open Policy Analysis standards with open data, open-source software, and research automation, can help the Green Deal policymaking process. Our collaboration is open for individuals, citizens scientists, research institutes, NGOS, and companies.
Challenge 2: An economy that works for people
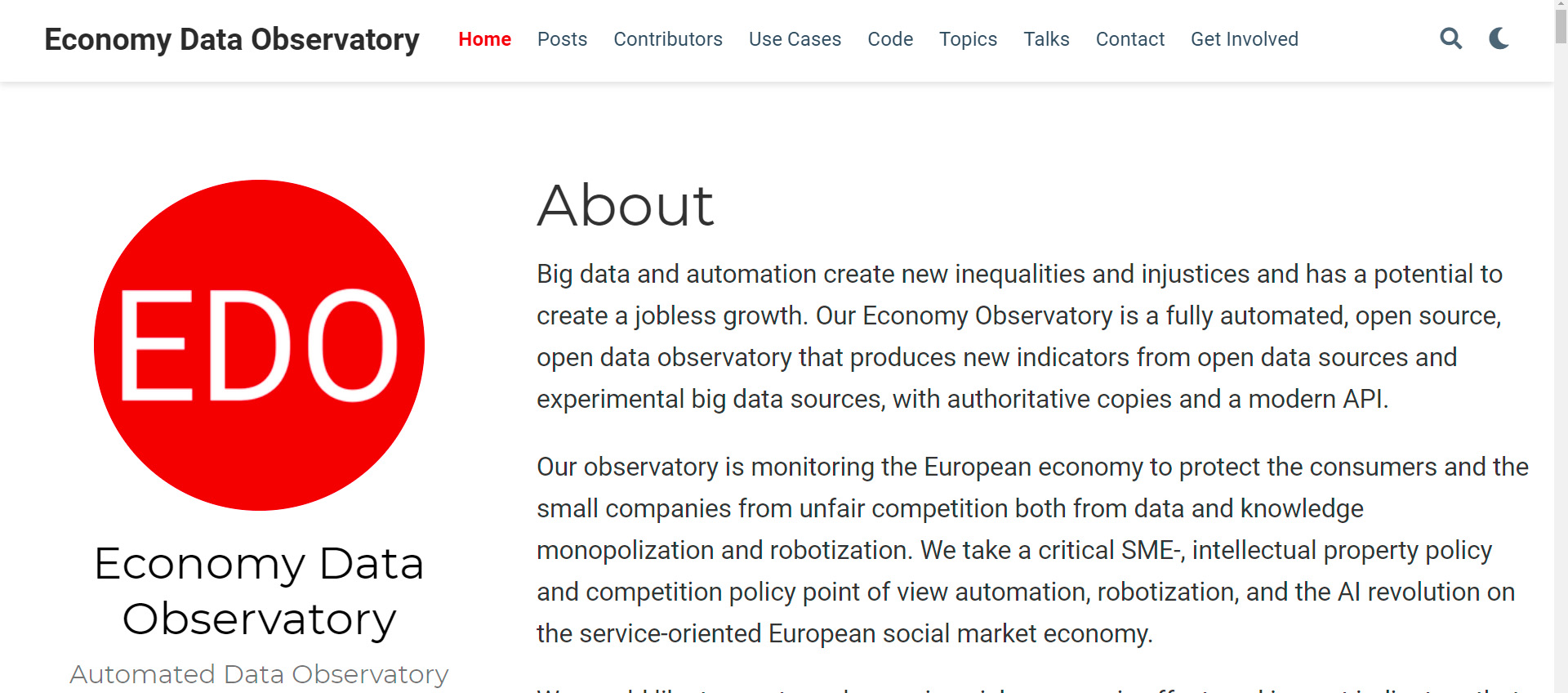
Challenge 2: An economy that works for people, with a particular focus on the Single market strategy, and particular attention to the strategy’s goals of 1. Modernising our standards system, 2. Consolidating Europe’s intellectual property framework, and 3. Enabling the balanced development of the collaborative economy strategic goals.
Big data and automation create new inequalities and injustices and have the potential to create a jobless growth economy. Our Economy Data Observatory is a fully automated, open source, open data observatory that produces new indicators from open data sources and experimental big data sources, with authoritative copies and a modern API.
Our observatory monitors the European economy to protect consumers and small companies from unfair competition, both from data and knowledge monopolization and robotization. We take a critical Small and Medium-Sized Enterprises (SME)-, intellectual property, and competition policy point of view of automation, robotization, and the AI revolution on the service-oriented European social market economy.
We would like to create early-warning, risk, economic effect, and impact indicators that can be used in scientific, business, and policy contexts for professionals who are working on re-setting the European economy after a devastating pandemic in the age of AI. We are particularly interested in designing indicators that can be early warnings for killer acquisitions, algorithmic and offline discrimination against consumers based on nationality or place of residence, and signs of undermining key economic and competition policy goals. Our goal is to help small and medium-sized enterprises and start-ups to grow, and to furnish data that encourages the financial sector to provide loans and equity funds for their growth.
Challenge 3: A Europe fit for the digital age
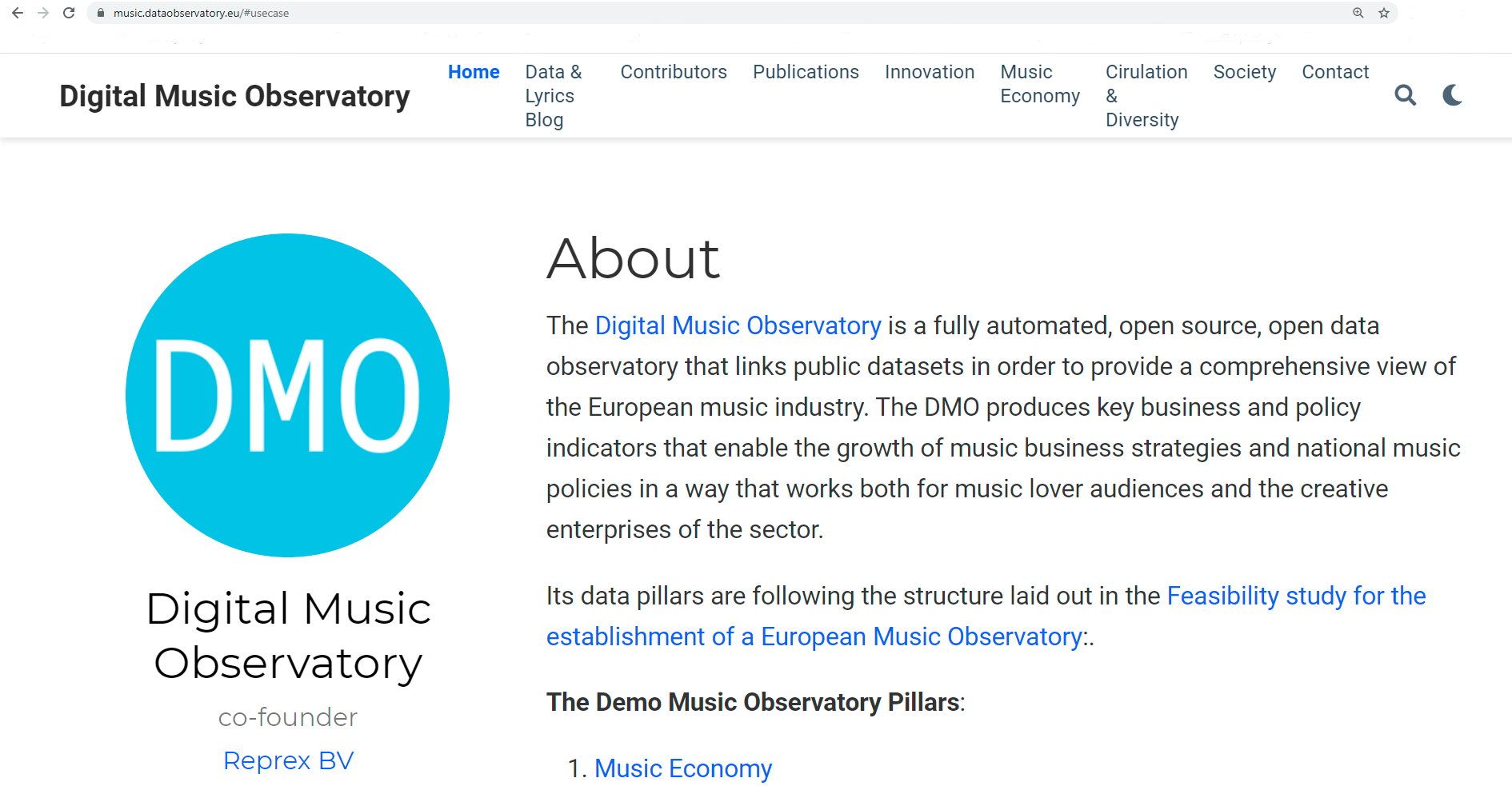
Challenge 3: A Europe fit for the digital age, with a particular focus Artificial Intelligence, the European Data Strategy, the Digital Services Act, Digital Skills and Connectivity.
The Digital Music Observatory (DMO) is a fully automated, open source, open data observatory that creates public datasets to provide a comprehensive view of the European music industry. It provides high-quality and timely indicators in all four pillars of the planned official European Music Observatory as a modern, open source and largely open data-based, automated, API-supported alternative solution for this planned observatory. The insight and methodologies we are refining in the DMO are applicable and transferable to about 60 other data observatories funded by the EU which do not currently employ governmental or scientific open data.
Music is one of the most data-driven service industries where most sales are currently executed by AI-driven autonomous systems that influence market shares and intellectual property remuneration. We provide a template that enables making these AI-driven systems accountable and trustworthy, with the goal of re-balancing the legitimate interests of creators, distributors, and consumers. Within Europe, this new balance will be an important use case of the European Data Strategy and the Digital Services Act.
The DMO is a fully functional service that can serve as a testing ground of the European Data Strategy. It can showcase the ways in which the music industry is affected by the problems that the Digital Services Act and European Trustworthy AI initiatives attempt to regulate. It is being built in open collaboration with national music stakeholders, NGOs, academic institutions, and industry groups.
Our Product/Market Fit was validated in the world’s 2nd ranked university-backed incubator program, the Yes!Delft AI Validation Lab. We are currently developing this project with the help of the JUMP European Music Market Accelerator program.
Problem Statement
The EU has an 18-year-old open data regime and it makes public taxpayer-funded data in the values of tens of billions of euros per year; the Eurostat program alone handles 20,000 international data products, including at least 5,000 pan-European environmental indicators.
As open science principles gain increased acceptance, scientific researchers are making hundreds of thousands of valuable datasets public and available for replication every year.
The EU, the OECD, and UN institutions run around 100 data collection programs, so-called ‘data observatories’ that more or less avoid touching this data, and buy proprietary data instead. Annually, each observatory spends between 50 thousand and 3 million EUR on collecting untidy and proprietary data of inconsistent quality, while never even considering open data.
The problem with the current EU data strategy is that while it produces enormous quantities of valuable open data, in the absence of common basic data science and documentation principles, it seems often cheaper to create new data than to put the existing open data into shape.
This is an absolute waste of resources and efforts. With a few R packages and our deep understanding of advanced data science techniques, we can create valuable datasets from unprocessed open data. In most domains, we are able to repurpose data originally created for other purposes at a historical cost of several billions of euros, converting these unused data assets into valuable datasets that can replace tens of millions’ worth of proprietary data.
What we want to achieve with this project – and we believe such an accomplishment would merit one of the first prizes - is to add value to a significant portion of pre-existing EU open data (for example, available on data.europa.eu/data) by re-processing and integrating them into a modern, tidy database with an API access, and to find a business model that emphasises a triangular use of data in 1. business, 2. science and 3. policy-making. Our mission is to modernize the concept of data observatories.
Our solution
We are empowering data curators with reproducible research solutions to create high-quality, rigorously tested original datasets from low quality, not validated, not tidy open data. We help them to design meaningful business, policy or scientific indicators and provide them with a software and API to keep the data up-to-date. We help them deposit a copy of the authoritative, uncompromised dataset onto Zenodo, the EU’s data repository, with a DOI or new DOI version.
We create a research workflow that periodically (daily, weekly, monthly, quarterly or annually) collects, corrects and re-processes the data. We use peer-reviewed statistical software and unit-tests to make sure that the data is sound.
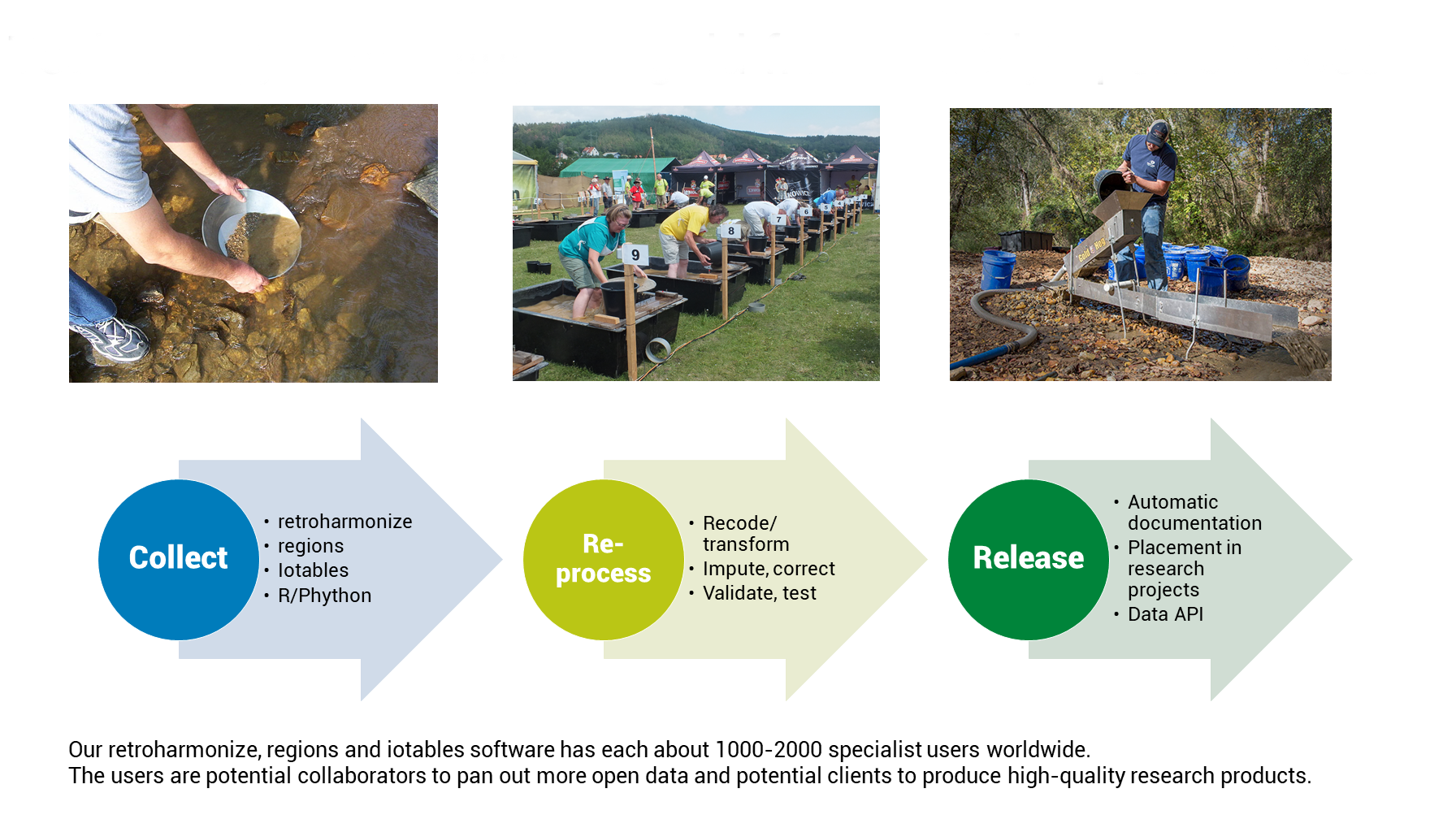
We add value with correcting open (and proprietary!) data problems that make open data hard to use, and proprietary, in-house data hard to re-use.
- regions corrects inconsistent geographical coding. Eurostat has no mandate to correct geographical coding, and member states do not historically adjust their data. With many thousands of parish, county, region, province, state boundary changes within states, regional and metropolitian area datasets are not usable without our software.
- iotables puts extremely complex national accounts data into actually useful environmental and economic impact indicators. Instead of working with each country separately, our standardized system can calculate direct and indirect effects, as well as multipliers for every European country that works in the European statistical framework (EU member states, EEA, UK, member candidates.)
- retroharmonize connects cross-sectional surveys with non-European countries, puts pan-European surveys into time series, and corrects regional subsamples. We are creating new indicators from Eurobarometer, Afrobarometer, Arab Barometer, and standardized CAP surveys, as well as other harmonized surveys. We help design surveys that can utilize data from already existing, openly available surveys.
We place the authoritative copy to a data repository (Zenodo or Dataverse), automatically document the data, and make it available in a modern API for SQL queries or CSV downloads.
We present the data with commentary and blog posts from our curators (see: Is Drought Risk Uninsurable? - solidarity and climate change in Belgium) and contributors on a semi-automatically refreshed, open source web portal.
We are perfecting the agile open collaboration model in a triangular setting, where corporate users, scientific researchers, public and non-governmental policy makers, and even citizen scientists can work around a single data ecoystem.
We are validating a business model that allows the commercial, scientific, and policy use of re-processed, high quality data products made from open and shared data.